|
Entre las nuevas funciones de BBj 6 está el respaldo
a disparadores (triggers) y procedimientos almacenados (stored
procedures)
en el sistema nativo de bases
de datos. Estos triggers y stored
procedures desarrollados en BBj se integran al sistema de
base de datos y pueden invocarse en accesos
SQL tanto de aplicaciones
en BBj como en otros lenguajes. Facilita grandemente la implementación
de integridad relacional y esquemas de seguridad en la base
de datos independientemente de lo que intente hacer la aplicación.
Los triggers son bloques de código que se ejecutan
cuando ocurren eventos de lectura, escritura o remoción
de columnas (registros).
Estos
bloques
pueden
ejecutarse antes, después o en lugar del evento.
Digamos que interesa verificar que un cliente no tiene
facturas pendientes de pago antes de poder eliminarlo del
sistema de Cuentas por Cobrar. Si se hace en la aplicación,
esta verificación es responsabilidad de cada procedimiento
que permita borrar un cliente. La ventaja de hacerlo con
un trigger es que esa verificación está centralizada
en la base de datos y puede rechazarse cualquier intento
de remoción
que no cumpla con la condición
deseada. Tanto
la
definición
del trigger
(XML)
como
el
bloque de código (BBj) se almacenan con
la base de datos a través del Enterprise Manager.
Como están
implementados a nivel de base de datos, operan tanto
en aplicaciones
que
usen READ/WRITE
como
aplicaciones
que usen SQL. Este es un ejemplo de la colocación
de triggers:
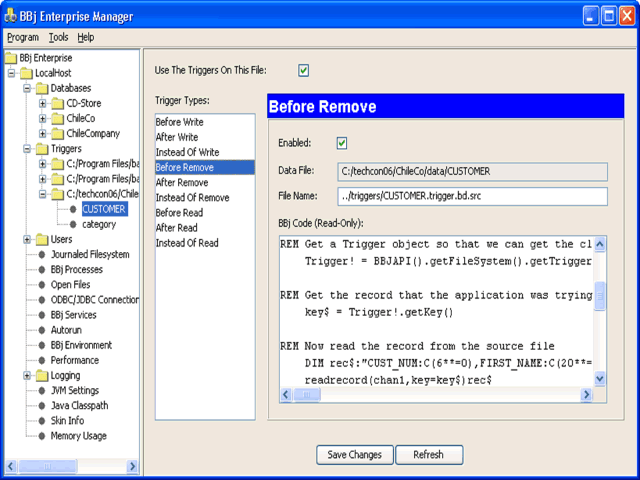
Los stored procedures (SPROC) son bloques de código
escritos en BBj que se colocan con la base de datos y extienden
las funciones ejecutables por SQL. Integran la lógica
de la aplicación con los datos, permitiendo implementar
un interface programático (API) para procedimientos
comunes. Los SPROC aceptan argumentos
y pueden devolver resultados usando los tipos de datos de
SQL. Pueden ser invocados tanto por aplicaciones en BBj como
por cualquier aplicación que pueda ejecutar procedimientos
de SQL. Al ejecutarse con la base de datos el rendimiento
también es óptimo. Digamos que necesita saber
el balance del cliente en varias partes de la aplicación
de Cuentas por Cobrar. La lógica para calcular esto
requiere enumerar las facturas abiertas, créditos
y pagos parciales. En lugar de colocar esta lógica
en cada procedimiento que lo necesite, puede definir un SPROC
en la base de datos que acepte como argumento el identificador
del cliente y produzca como resultado el balance actual de
su cuenta. Los procedimientos que lo necesiten pueden invocar
el SPROC con sólo ejecutar un SQL SELECT con la función
y sus argumentos. Como toda la lógica se ejecuta en el servidor
de base de datos, se minimiza el tráfico en la
red maximizando
así el rendimiento.
BBj 6 respalda también varios nuevos tipos de archivos
optimizados para mayor funcionabilidad y rendimiento en ciertos
tipos
de aplicaciones. Los archivos XKEYED permiten un número
prácticamente
ilimitado de índices con un largo de índice
prácticamente
ilimitado y usando un espacio en disco menor que
archivos MKEYED. Los archivos JKEYED usan "journaling" y
están diseñados para procesamiento
de transacciones (transaction tracking) con buen rendimiento
en COMMITs y ROLLBACKs.
Los archivos
VKEYED ofrecen espacio de disco reducido en registros con
variaciones significativas de largo. Probablemente el nuevo
tipo de archivo que generó más interés
fue el ESQL. Los archivos ESQL no respaldan READ/WRITE sino
que están diseñados exclusivamente
para ejecutación más rápida de comandos
de SQL. Pruebas usando SQL en archivos ESQL muestran tiempos
de respuesta entre
2 y 7 veces más bajos que usando SQL en archivos
MKEYED. Desarrolladores que interesen respaldar SQL en sus
aplicaciones
usando bases de datos nativas deben considerar los nuevos
archivos ESQL.
Para más detalles,
dos de las presentaciones de Techcon 2006 sobre bases de
datos están disponibles abajo en formato PowerPoint.
Pueden acceder a documentación de las nuevas funciones
y tipos de archivos en el manual de referencia (enlaces abajo).
|
